コラム
AWS Lake Formationで行およびセルレベルのきめ細かなアクセス制御が可能になりました
-
TAG
タグ未登録 -
UPDATE
2021/12/13




はじめに
こんにちは、クラウドCoEの城前です。
AWS re:Invent 2021でAWS Lake Formationが行レベルとカラムレベルでのセキュリティのサポートがついにGAとなったことを発表しました。
セキュリティが強化されたことで、より簡単に機密情報へのアクセスを制限できるようになり、より安全にデータレイクをセットアップできるようになりました。是非有効活用してください。
https://aws.amazon.com/jp/about-aws/whats-new/2021/11/aws-lake-formation-governed-tables-storage-security/
今回はこのアップデートについてどのような挙動になるのかを実際にやってみたいと思います。
AWS Lake Formationとは
AWS Lake Formationとは、安全なデータレイクをすばやくセットアップできるサービスです。
Glue の拡張機能と言え、セキュリティ強化やブループリントによるデータ取り込みなどでより便利にGlueの機能を使えるようになっており、以下のコンポーネントが用意されています。
- データ取り込みと構造化⇒ブループリント:汎用的なデータ取り込みテンプレートを使い、自動的なデータ取り込みを構造化を実現
- セキュリティ&コントロール⇒パーミッション:SQLライクなGrant/Revokeでシンプルなアクセス制御を実現
- 協調&利用⇒データカタログ:スキーマやロケーションなどのデータのメタ情報を管理し、ファセット検索で探したいデータセットを検索
- 監視&監査⇒ロギング:コンソールによる直近のアクティビティの詳細が確認可能
ユースケース
次にユースケースですが、S3上に配置されている顧客情報などの機密情報が含まれる購入履歴データに対して、データアナリストがアクセスし分析とマーケティングを行う場合を例とします。
- 顧客情報が含まれるカラムにはアクセスをさせたくない
- マーケティングチームのデータアナリストは国ごとに分かれており、各データアナリストは自国のデータのみにアクセスを制限させたい
といった条件がある場合に従来は「全てのデータから個人情報が含まれるカラムを削除した上で、新たにS3でデータを格納する」や「国毎にテーブルを複製しS3に格納する」といった処理を行う必要があり、以下の問題点を抱えていました。
- ロールごとのデータの複製によるコストストレージの増大
- ETL処理の構築と運用の負荷の増加
- 権限管理対象の増加に伴う管理負荷の増加
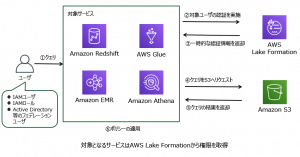
しかし、AWS Lake FormationのData Filteringを使用することで、S3 データレイクのテーブルに対する列、行、およびセルレベルのアクセス許可を付与できるようになりました。
これにより1つのテーブルからペルソナに応じたアクセスパターンのデータビューを提供することが可能になりさまざまなロールや法規制ごとにデータのサブセットを作成 (および更新) する必要がなくなりました。
尚、AWS Lake Formationが提供する認可は以下のようなフローとなっています。
やってみた
AWS Lake FormationではCloudTrailをソースとしてデータレイクを作成するチュートリアルが用意されています。せっかくなのでこのチュートリアルを実施し、取り込んだCloudTrailログに対してData Filteringを使用したアクセス制限の付与を行っていきたいと思います。
設定後にAthenaから実際にアクセスし、行およびセルレベルでのアクセス制御が有効であることを確認します。
作業1
長くなるので本ブログではチュートリアル部分は割愛しますが、以下のドキュメントを参考に設定を行います
https://docs.aws.amazon.com/lake-formation/latest/dg/getting-started-cloudtrail-tutorial.html
チュートリアル実施後は作成したワークフローが「Complete」となり、データレイクとして登録したS3バケットにCloudTrailのログが登録されているかと思います。
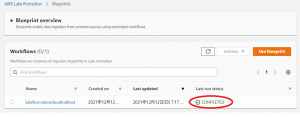
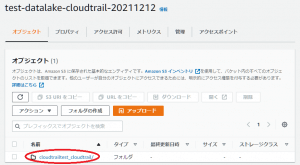
作業2
次にData Filteringの作成を行います。
AWS Lake Formationのコンソールの「Data catalog」→「Data filters」から作成します。
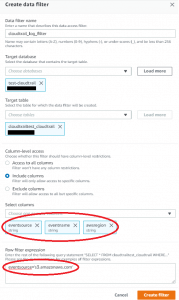
まずチュートリアルで作成したデータベースとテーブルを指定します。
「Column-level access」項目では「Include columns」を選択し、eventsource、eventname、awsregionのカラムのみをアクセス許可し、かつ「Row filter expression」項目に「eventsource=’s3.amazonaws.com’」という条件を指定し、eventsource列がs3.amazonaws.comとなっている行のみにアクセスを制限するフィルターを作成します。
作業3
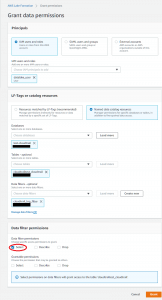
次にチュートリアルのStep1で作成したIAMユーザ(datalake_user)に手順2で作成したData filtersを付与し、さらにSelect権限の付与を行います。
AWS Lake Formationのコンソールの「Permissions」→「Data lake permissions」→「Grant」から設定を行います。
手順4
AWS Lake FormationではAWS Glueとの下位互換性を維持するために、以下の初期セキュリティ設定が行われています。
・既存のすべてのAWS Glue Data Catalogリソースに対して、グループIAMAllowedPrincipalsにSuperパーミッションが付与されます。
・”Use only IAM access control “の設定は、新しいデータカタログリソースに対して有効になっている。
これらの設定により、データカタログリソースとAmazon S3へのアクセスがIAMポリシーのみによって制御されるようになり、手順3で作成した権限付与が有効になりません。
そのため、以下ドキュメントを参考に各データベースのセキュリティ設定を変更します。
https://aws.amazon.com/jp/premiumsupport/knowledge-center/troubleshoot-lakeformation-data-catalog-permissions/
手順5
AthenaからAWS Lake Formationで管理されているテーブルに対してクエリを実行するには、「AmazonAthenaLakeFormation」というワークグループを使用する必要があります。
以下ドキュメントを参考に「AmazonAthenaLakeFormation」ワークグループの作成を行います。
https://docs.aws.amazon.com/athena/latest/ug/lf-governed-tables.html
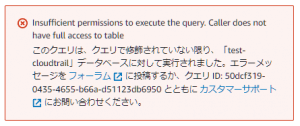
尚、デフォルトのワークグループ(primary)でクエリを実行しようとした場合、以下のエラーメッセージが出力されます。
エラーメッセージ:Insufficient permissions to execute the query. Caller does not have full access to table
動作確認
これでようやくAthenaからクエリを実行することができます。
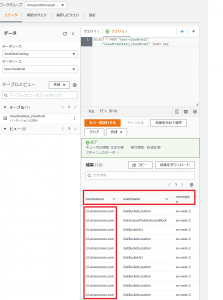
手順2で作成したData Filteringの通り、アクセス制御が行えているか以下の流れで確認してみます。
- 手順1のチュートリアルで作成したIAMユーザ(datalake_user)でログイン
- Athenaのコンソール画面に遷移
- 手順5で作成したワークグループ「AmazonAthenaLakeFormation」に切り替える
- データソースから「AwsDataCatalog」を選択
- データベースから手順1のチュートリアルで作成したデータベースを選択
- 画面からクエリを発行
Data Filteringで指定した通りのカラムと条件(eventsource=’s3.amazonaws.com’)に該当するデータのみ出力されることが確認できました。
今回は以上となります。
-
PICK UP
ピックアップ
-
ピックアップコンテンツがありません
-
RANKING
人気の記事
-
-
1

EKSを理解する(第2回)IRSAを用いたPod単…
EKSを理解する(第2回)IRSAを用いたPod単位のIAMロール割り当て
2020/09/08
-
2

Azure ADテナント作成/Azureサブスクリ…
Azure ADテナント作成/Azureサブスクリプション契約時に検討すべきこと
2022/02/02
-
3

Tableau ServerリポジトリをAmazo…
Tableau ServerリポジトリをAmazon RDSで構築する方法
2022/05/18
-
4

AWS Pricing Calculaterのスス…
AWS Pricing Calculaterのススメ
2023/03/21
-
5
AWS CloudFormationでBlueGr…
AWS CloudFormationでBlueGreenデプロイを実現してみた(…
2019/10/25
-

-
ARCHIVE
アーカイブ
-
- July 2024 (1)
- January 2024 (1)
- December 2023 (2)
- June 2023 (2)
- May 2023 (1)
- April 2023 (1)
- March 2023 (2)
- February 2023 (2)
- January 2023 (1)
- December 2022 (2)
- October 2022 (2)
- September 2022 (2)



